《Java SE》
Java 概述
什么是java
Java 是一门面向对象的高级编程语言。它吸收了 C++ 语言中的大量优点,但又抛弃了 C++ 中容易出错的地方,如垃圾回收、指针。
同时,Java 又是一门平台无关性的语言,基于对应操作系统的 JVM 实现跨平台性。
语言特点
- 面向对象,封装、继承、多态。
- 跨平台性,拥有很好的可移植性。
- 支持多线程以及即时编译。
JVM、JRE、JDK
JVM:是 Java 虚拟机,不同的平台有不同的 JVM 实现,是 Java 跨平台性的基石。JVM 负责将字节码文件解释为该平台的机器码。
JRE:是 Java 的运行环境,包含必需的类库和 JVM。
JDK:是一套完整的 Java 程序开发环境,包括了 JRE 、JVM、编译器 javac、文档工具 javadoc、字节码工具 javap 等。
基础语法
数据类型
-
数值型:
- 整数类型:byte、short、int、long
- 浮点类型:float、double
-
字符型:char
-
布尔型:boolean
数据类型 默认值 大小 byte 0 1 byte short 0 2 byte int 0 4 byte long 0.0L 8 byte float 0.0f 4 byte double 0.0 8 byte char ‘\u0000’ 2 byte boolean false -
引用性:
- 类:class
- 接口:interface
- 数组:[]
数据类型转换
自动类型转换(自动类型提升)
这是 Java 编译器在不需要显式转换的情况下,将一种基本数据类型转换为另一种基本数据类型的过程。通常发生在表达式求值期间不同数据需要互相兼容时。
- 如果任一操作数是 double 类型,其他操作数将被转换为 double 类型。
- 否则,如果任一操作数是 float 类型,其他操作数将被转换为 float 类型。
- 否则,如果任一操作数是 long 类型,其他操作数将被转换为 long 类型。
- 否则,所有操作数将被转换为 int 类型。
强制类型转换
这是 Java 中将一种数据类型显式转换为另一种数据类型的过程,需要程序员显式地指定。强制类型转换可能会导致数据丢失或精度降低,需要确保转换后的值仍然在目标类型的范围内。
自动拆箱/装箱
- 装箱:基本数据类型转换为包装类对象。
- 拆箱:包装类对象转换为基本数据类型。
| 基本类型 | 包装类 |
|---|---|
int |
Integer |
boolean |
Boolean |
char |
Character |
byte |
Byte |
short |
Short |
long |
Long |
float |
Float |
double |
Double |
& 和 &&
& 是 逻辑与,&& 是 短路与。二者都要求运算符左右两端的布尔值都是 true,整个表达式的值才是 true。但是 && 左边的表达式的值是 false 时,右边的表达式会直接短路掉,不会进行运算。
逻辑或运算符(|)和短路或运算符(||)的差别也是类似。
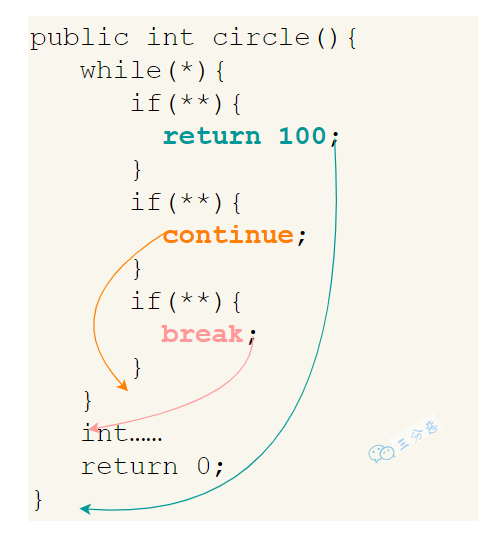
break、continue、return
- break 跳出整个循环,不再执行循环(结束当前的循环体)
- continue 跳出本次循环,继续执行下次循环(结束正在执行的循环 进入下一个循环条件)
- return 程序返回,不再执行下面的代码(结束当前的方法 直接返回)
面向对象
面向对象和面向过程的区别
面向过程时以过程为核心,通过函数完成任务,结构是函数+步骤组成的顺序流程。
面向对象是以对象为核心,通过对象交互完成,结构是类和对象组成的模块化结构,代码可以通过继承、组合、多态等方式复用。
面向对象编程的特性
面向对象有三大特性:封装、继承、多态。
- 封装:将数据(属性/字段)和方法捆绑在一起,形成一个独立的对象(类的实例),私有化属性并提供外界可以访问的方法。
- 继承:允许一个类(子类)继承现有类(父类/基类)的属性和方法。提高代码的复用性,建立类之间的层次关系。子类可以重写或扩展从父类继承来的属性和方法。
- 多态:同一个接口或方法在不同的类中有不同的实现,比如说动态绑定,父类引用指向子类对象,方法的具体调用在运行时决定。前置条件:
- 子类继承父类
- 子类重写父类的方法
- 父类引用指向子类的对象
多组合少继承
继承容易导致类之间的强耦合,一旦父类发生改变,子类也要随之改变,违背了开闭原则(尽量不修改现有代码,而是添加新的代码来实现)。
组合通过在类中组合其他类,能够灵活地扩展功能,避免了复杂的类继承体系,同时遵循了开闭原则和低耦合的设计原则。
多态的实现原理
多态通过动态绑定实现,Java 使用虚方法表存储方法指针,方法调用时根据对象实际类型从虚方法表查找具体实现。
重载和重写
- 重载:一个类所拥有的名字相同但参数个数不同的方法,可以提高代码的可读性。
- 重写:子类和父类有一样的方法(参数相同、返回类型相同、方法名相同、但方法体可能不同),用于提供父类已经声明的方法的特殊实现,是实现多态的基础条件。
设计原则
里氏代换原则(LSP)
任何父类可以出现的地方,子类也一定可以出现。LSP 是继承复用的基石,只有当子类可以替换掉父类,并且单位功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为。因此子类在扩展父类时,不应改变父类原有的行为。
单一职责原则(SRP)
一个类应该只有一个引起它变化的原因,即一个类只负责一项职责。目的是使类更加清晰,更容易理解和维护。
开闭原则(OCP)
软件实体应该对扩展开发,对修改关闭。一个类应该通过扩展来实现新的功能,而不是通过修改已有的代码来实现。
接口隔离原则(ISP)
客户端不应该依赖它不需要的接口。设计接口时应该尽量精简,不应该设计臃肿庞大的接口。
依赖倒置原则(DIP)
高层模块不应该依赖底层模块,二者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。设计时应该尽量依赖接口或抽象类,而不是实现类。
访问修饰符
Java 中,可以使用访问控制符来对保护类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
- default(默认,留空):在同一包内可见。可以修饰类、接口、变量、方法。
- private:在同一类可见。可以修饰变量、方法。不能修饰类(外部类)。
- public:对所有类可见。可以修饰类、接口、变量、方法。
- protected:对同一包内的类和所有子类可见。可以修饰变量、方法。不能修饰类(外部类)。
关键字
this关键字
this 是自身的一个对象,代表对象本身,可以理解为**:指向对象本身的一个指针**。
this 的用法大体可以分为 3 种:
-
普通的直接引用,this 相当于是指向当前对象本身。
-
形参与成员变量名字重名,用 this 来区分:
public Person(String name,int age){
this.name=name;
this.age=age;
} -
引用本类的构造方法。
static 关键字
static 关键字可以用来修饰变量、方法、代码块和内部类,以及导入包。
| 修饰对象 | 作用 |
|---|---|
| 变量 | 静态变量,类级别变量,所有实例共享同一份数据。 |
| 方法 | 静态方法,类级别方法,与实例无关。 |
| 代码块 | 在类加载时初始化一些数据,只执行一次。 |
| 内部类 | 与外部类绑定但独立于外部类实例。 |
| 导入 | 可以直接访问静态成员,无需通过类名引用,简化代码书写,但会降低代码可读性。 |
静态变量和实例变量的区别
静态变量:是被 static 修饰符修饰的变量,也称为类变量,它属于类;不属于类的任何一个对象,一个类不管创建多少个对象,静态变量在内存中有且仅有一个副本。
实例变量:必须依存于某一实例,需要先创建对象然后通过对象才能访问到它。静态变量可以实现多个对象共存。
静态方法和实例方法的区别
静态方法:static 修饰的方法,也被称为类方法。在外部调⽤静态⽅法时,可以使⽤"类名.⽅法名"的⽅式,也可以使⽤"对象名.⽅法名"的⽅式。静态方法里不能访问类的非静态成员变量和方法。
实例⽅法:依存于类的实例,需要使用"对象名.⽅法名"的⽅式调用;可以访问类的所有成员变量和方法。
final 关键字
- 当 final 修饰类时,这个类不能被继承。
- 当 final 修饰方法时,这个方法不能被重写(Override)。
- 当 final 修饰变量时,这个变量的值一旦被初始化就不能修改.
- 如果是基本数据类型的变量,其数值一旦在初始化后就不能更改。
- 如果是引用数据类型的变量,在对其初始化之后就不能再让其指向另一个对象,但是引用指向的对象内容可以改变。
final、finally、finalize 的区别
- final 是一个修饰符,可以修饰类、方法和变量。当 final 修饰类时,该类不能被继承;修饰方法时,该方法不能被重写;修饰变量时,该变量被赋值就不能更改。
- finally 是 Java 中异常处理的一部分,用来创建 try 块后面的 finally 块。无论 try 块中的代码是否抛出异常,finally 块中的代码总是会被执行。finally 块通常用来释放资源(关闭文件、数据库连接)。
- finalize 是 Object 类的一个方法,用于在垃圾回收器将对象从内存中清除出去之前做一些必要的清理工作。该方法被自动调用,我们不能显式地调用。
抽象、接口、多继承
抽象类和接口
一个类只能继承一个抽象类;但一个类可以实现多个接口。所有我们在新建线程类的时候一般推荐使用实现 Runnable 接口的方式,这样线程类还可以继承其他类。
抽象类符合 is-a 的关系,接口更符合 has-a 的关系,比如说一个类可以序列化的时候,它只需要实现 Serializable 接口就可以了,不需要去继承一个序列化类。
抽象类更多地是用来为多个相关的类提供一个共同的基础框架,包括状态的初始化,而接口则是定义一套行为标准,让不同的类可以实现同一接口,提供行为的多样化实现。
抽象类可以有构造方法,但是接口不可以有构造方法,接口主要用于定义一直方法规范,没有具体的实现细节。
多继承
Java 不支持多继承,一个类只能继承一个类,多继承会引发菱形继承问题。
接口可以多继承,一个接口可以继承多个接口,使用逗号分隔。
继承和抽象,抽象类和普通类
继承是一种允许子类继承父类属性和方法的机制。通过继承,子类可以重用父类的代码。
抽象是一种隐藏复杂性和只显示必要部分的技术。在面向对象编程中,抽象可以通过抽象类和接口实现。
抽象类使用 abstract 关键字定义,不能被实例化,只能作为其他类的父类。普通类没有 abstract 关键字,可以直接实例化。
抽象类可以包含抽象方法和非抽象方法。抽象方法没有方法体,必须由子类实现。普通类只能包含非抽象方法。
变量
成员变量和局部变量
- 从语法上看:成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
- 从变量在内存中的存储方式来看:如果成员变量是使用 static 修饰的,那么这个成员变量是属于类的,如果没有属于 static 修饰,这个成员变量是属于实例的。对象存于堆内存,如果局部变量类型为基本数据类型,那么存储在栈内存,如果为引用数据类型,那存放的是指向堆内存对象的引用或者是指向常量池中的地址。
- 从变量在内存中的⽣存时间上看:成员变量是对象的⼀部分,它随着对象的创建⽽存在,⽽局部变量随着⽅法的调⽤⽽⾃动消失。
- 成员变量如果没有被赋初值:则会⾃动以类型的默认值⽽赋值(⼀种情况例外:被 final 修饰的成员变量也必须显式地赋值),⽽局部变量则不会⾃动赋值。
== 和 equals 的区别
在 Java 中,== 操作符和 equals() 方法用于比较两个对象:
-
==:用于比较两个对象的引用,即它们是否指向同一个对象实例。
如果两个变量引用同一个对象实例,
==返回true,否则返回false。 对于基本数据类型(如
int,double,char等),==比较的值是否相等。 -
equals() 方法:用于比较两个对象的内容是否相等。默认情况下,
equals()方法的行为与==相同,即比较对象引用,如在超类 Object 中:
public boolean equals(Object obj) { |
然而,equals() 方法通常被各种类重写。例如,String 类重写了 equals() 方法,以便它可以比较两个字符串的字符内容是否完全一样。
重写 equals 时必须重写 hashCode 方法
因为基于哈希的集合类(如 HashMap)需要基于这一点来正确存储和查找对象。
具体地说,HashMap 通过对象的哈希码将其存储在不同的“桶”中,当查找对象时,它需要使用 key 的哈希码来确定对象在哪个桶中,然后再通过 equals() 方法找到对应的对象。
如果重写了 equals()方法而没有重写 hashCode()方法,那么被认为相等的对象可能会有不同的哈希码,从而导致无法在 HashMap 中正确处理这些对象。
什么是 hashCode 方法
hashCode() 方法的作⽤是获取哈希码,它会返回⼀个 int 整数,定义在 Object 类中, 是一个本地⽅法。
public native int hashCode(); |
为什么要有 hashCode 方法
hashCode 方法主要用来获取对象的哈希码,哈希码是由对象的内存地址或者对象的属性计算出来的,它是⼀个 int 类型的整数,通常是不会重复的,因此可以用来作为键值对的建,以提高查询效率。
为什么两个对象有相同的 hashCode 值,它们也不一定相等
这主要是由于哈希码(hashCode)的本质和目的所决定的。
哈希码是通过哈希函数将对象中映射成一个整数值,其主要目的是在哈希表中快速定位对象的存储位置。
由于哈希函数将一个较大的输入域映射到一个较小的输出域,不同的输入值(即不同的对象)可能会产生相同的输出值(即相同的哈希码)。
这种情况被称为哈希冲突。当两个不相等的对象发生哈希冲突时,它们会有相同的 hashCode。
为了解决哈希冲突的问题,哈希表在处理键时,不仅会比较键对象的哈希码,还会使用 equals 方法来检查键对象是否真正相等。如果两个对象的哈希码相同,但通过 equals 方法比较结果为 false,那么这两个对象就不被视为相等。
if (p.hash == hash && |
hashCode 和 eauals 方法的关系
如果两个对象通过 equals 相等,它们的 hashCode 必须相等。否则会导致哈希表类数据结构(如 HashMap、HashSet)的行为异常。
在哈希表中,如果 equals 相等但 hashCode 不相等,哈希表可能无法正确处理这些对象,导致重复元素或键值冲突等问题。
值传递和引用传递
Java 是值传递,不是引用传递,当一个对象被作为参数传递到方法中时,参数的值就是该对象的引用。引用的值是对象在堆中的地址。
对象是存储在堆中的,所以传递对象的时候可以理解为把变量存储的对象地址给传递过去。引用类型的变量存储的是对象的地址,而不是对象本身。因此,引用类型的变量在传递时,传递的是对象的地址,也就是说传递的是引用的值。
深拷贝和浅拷贝的区别
在 Java 中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是两种拷贝对象的方式,它们在拷贝对象的方式上有很大不同。
浅拷贝会创建一个新对象,但这个新对象的属性(字段)和原对象的属性完全相同。如果属性是基本数据类型,拷贝的是基本数据类型的值;如果属性是引用类型,拷贝的是引用地址,新旧对象共享同一个引用对象。
浅拷贝的实现方式:实现 Cloneable 接口并重写 clone 方法。
class Person implements Cloneable { |
深拷贝也会创建一个新对象,但会递归地复制所有的引用对象,确保新对象和原对象完全独立。新对象与原对象的任何更改都不会相互影响。
深拷贝的实现方式有两种:手动复制所有的引用对象或者使用序列化和反序列化。
-
手动拷贝
class Person {
String name;
int age;
Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
public Person(Person person) {
this.name = person.name;
this.age = person.age;
this.address = new Address(person.address.city);
}
}
class Address {
String city;
public Address(String city) {
this.city = city;
}
}
public class Main {
public static void main(String[] args) {
Address address = new Address("地址 ");
Person person1 = new Person("姓名", 18, address);
Person person2 = new Person(person1);
System.out.println(person1.address == person2.address); // false
}
} -
序列化和反序列化
import java.io.*;
class Person implements Serializable {
String name;
int age;
Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
public Person deepClone() throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Person) ois.readObject();
}
}
class Address implements Serializable {
String city;
public Address(String city) {
this.city = city;
}
}
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Address address = new Address("地址");
Person person1 = new Person("姓名", 18, address);
Person person2 = person1.deepClone();
System.out.println(person1.address == person2.address); // false
}
}创建对象的方式
Java 有四种创建对象的方式:
-
new 关键字创建,这是最常见和直接的方式,通过调用类的构造方法来创建对象。
Person person = new Person();
-
反射机制创建,反射机制允许在运行时创建对象,并且可以访问类的私有化成员,在框架和工具类中比较常见。
Class clazz = Class.forName("Person");
Person person = (Person) clazz.newInstance(); -
clone 拷贝创建,通过 clone 方法创建对象,需要实现 Cloneable 接口并重写 clone 方法。
Person person = new Person();
Person person2 = (Person) person.clone(); -
序列化机制创建,通过序列化将对象转换为字节流,再通过反序列化从字节流中恢复对象。需要实现 Serializable 接口。
Person person = new Person();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.txt"));
oos.writeObject(person);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.txt"));
Person person2 = (Person) ois.readObject();
new 子类的时候,子类和父类的静态代码块、构造方法的执行顺序:
执行顺序遵循一定的规则,主要包括以下几个步骤:
- 首先执行父类的静态代码块(仅在类第一次加载时执行)。
- 接着执行子类的静态代码块(仅在类第一次加载时执行)。
- 在执行父类的构造方法。
- 最后执行子类的构造方法。
示例:
class Parent {
// 父类静态代码块
static {
System.out.println("父类静态代码块");
}
// 父类构造方法
public Parent() {
System.out.println("父类构造方法");
}
}
class Child extends Parent {
// 子类静态代码块
static {
System.out.println("子类静态代码块");
}
// 子类构造方法
public Child() {
System.out.println("子类构造方法");
}
}
public class Main {
public static void main(String[] args) {
new Child();
}
}结果:
父类静态代码块
子类静态代码块
父类构造方法
子类构造方法 -
-
静态代码块:在类加载时执行,仅执行一次,按父类-子类的顺序执行。
-
构造方法:在每次创建对象时执行,按父类-子类的顺序执行,先初始化代码块后构造方法。
String
String 是基本数据类型吗,可以被继承吗
String 是一个类,属于引用数据类型。String 类使用 final 修饰,是不可变类,无法被继承。
常用方法
length()- 返回字符串的长度。charAt(int index)- 返回指定位置的字符。substring(int beginIndex, int endIndex)- 返回字符串的一个子串,从beginIndex到endIndex-1。contains(CharSequence s)- 检查字符串是否包含指定的字符序列。equals(Object anotherObject)- 比较两个字符串的内容是否相等。indexOf(int ch)和indexOf(String str)- 返回指定字符或字符串首次出现的位置。replace(char oldChar, char newChar)和replace(CharSequence target, CharSequence replacement)- 替换字符串中的字符或字符序列。trim()- 去除字符串两端的空白字符。split(String regex)- 根据给定正则表达式的匹配拆分此字符串。
String、StringBuilder 和 StringBuffer 的区别
String 、 StringBuilder 和 StringBuffer 在 Java 中都是用于处理字符串的,它们的区别是:String 是不可变的,平常开发用得最多,当遇到大量字符串连接时,就用 StringBuilder,它不会生成很多新的对象,StringBuffer 和 StringBuilder 类似,但每个方法都加了 synchronized 关键字,是线程安全的。
String 的特点
String类的对象是不可变的。一旦一个String对象被创建,它所包含的字符串内容是不可被改变的。- 每次对
String对象进行修改操作(如拼接、替换等)实际上都会生成一个新的String对象,而不是修改原有对象。这可能会导致内存和性能开销,尤其是在大量字符串操作的情况下。
StringBuilder 的特点
StringBuilder提供了一系列的方法来进行字符串的增删改查操作,这些操作都是直接在原有字符串对象的底层数组上进行的,而不是生成新的String对象。StringBuilder不是线程安全的。在没有外部同步的情况下不适用于多线程环境。- 相比
String,在进行频繁的字符串修改操作时,StringBuilder能提供更好的性能。Java 中的字符串连+操作就是通过StringBuilder实现的。
StringBuffer 的特点
StringBuffer和StringBuilder类似,但StringBuffer是线程安全的,方法前面都加了synchronized关键字。
使用场景
- String:适用于字符串内容不会改变的场景,比如说作为 HashMap 的 key。
- StringBuilder:适用于单线程环境下需要频繁修改字符串内容的场景,比如在循环中拼接或修改字符串,是 String 的完美替代品。
- StringBuffer:现在已经不怎么用了,因为一般不会在多线程场景下去频繁的修改字符串内容。
String str1 = new String(“abc”) 和 String str2 = “abc” 的区别
直接使用双引号为字符串变量赋值时,Java 首先会检查字符串常量池中是否已经存在相同内容的字符串。如果存在,Java 会让新的变量引用常量池中的那个字符串;如果不存在,就会创建一个新的字符串放入常量池并引用它。
使用 new String("abc") 的方式创建字符串时,实际分为两步:
- 第一步,先检查字符串字面量 “abc” 是否在字符串常量池中,如果没有则创建一个;如果已经存在,则引用它。
- 第二步,在堆中再创建一个新的字符串对象,并将其初始化为字符串常量池中 “abc” 的一个副本。
String s = new String(“abc”)创建了几个对象?
字符串常量池中如果之前已经有一个,则不再创建新的,直接引用;如果没有,则创建一个。
堆中肯定有一个,因为只要使用了 new 关键字,肯定会在堆中创建一个。
String 是不可变类吗?字符串拼接是如何实现的?
String 是不可变的,这意味着一旦一个 String 对象被创建,其存储的文本内容就不能被改变。这是因为:
①、不可变性使得 String 对象在使用中更加安全。因为字符串经常用作参数传递给其他 Java 方法,例如网络连接、打开文件等。
如果 String 是可变的,这些方法调用的参数值就可能在不知不觉中被改变,从而导致网络连接被篡改、文件被莫名其妙地修改等问题。
②、不可变的对象因为状态不会改变,所以更容易进行缓存和重用。字符串常量池的出现正是基于这个原因。
当代码中出现相同的字符串字面量时,JVM 会确保所有的引用都指向常量池中的同一个对象,从而节约内存。
③、因为 String 的内容不会改变,所以它的哈希值也就固定不变。这使得 String 对象特别适合作为 HashMap 或 HashSet 等集合的键,因为计算哈希值只需要进行一次,提高了哈希表操作的效率。
字符串拼接是如何实现的?
因为 String 是不可变的,因此通过“+”操作符进行的字符串拼接,会生成新的字符串对象。
例如:
String a = "hello "; |
a 和 b 是通过双引号定义的,所以会在字符串常量池中,而 ab 是通过“+”操作符拼接的,所以会在堆中生成一个新的对象。
Java 8 时,JDK 对“+”号的字符串拼接进行了优化,Java 会在编译期基于 StringBuilder 的 append 方法进行拼接。所以通过加号拼接字符串时会创建多个 String 对象是不准确的。因为还会创建一个 StringBuilder 对象,最终调用 toString() 方法的时候再返回一个新的 String 对象。
如何保证 String 不可变?
第一,String 类内部使用一个私有的字符数组来存储字符串数据。这个字符数组在创建字符串时被初始化,之后不允许被改变。
private final char value[]; |
第二,String 类没有提供任何可以修改其内容的公共方法,像 concat 这些看似修改字符串的操作,实际上都是返回一个新创建的字符串对象,而原始字符串对象保持不变。
public String concat(String str) { |
第三,String 类本身被声明为 final,这意味着它不能被继承。这防止了子类可能通过添加修改方法来改变字符串内容的可能性。
public final class String |
intern 方法有什么作用?
- 如果当前字符串内容存在于字符串常量池(即 equals()方法为 true,也就是内容一样),直接返回字符串常量池中的字符串
- 否则,将此 String 对象添加到池中,并返回 String 对象的引用
Integer
Integer a= 127,Integer b = 127;Integer c= 128,Integer d = 128;相等吗?
a 和 b 相等,c 和 d 不相等。
这个问题涉及到 Java 的自动装箱机制以及Integer类的缓存机制。
对于第一对:
Integer a = 127; |
Integer.valueOf()方法会针对数值在-128 到 127 之间的Integer对象使用缓存。因此,a和b实际上引用了常量池中相同的Integer对象。
对于第二对:
Integer c = 128; |
c和d不相等。这是因为 128 超出了Integer缓存的范围(-128 到 127)。
因此,自动装箱过程会为c和d创建两个不同的Integer对象,它们有不同的引用地址。
可以通过==运算符来检查它们是否相等:
System.out.println(a == b); // 输出true |
要比较Integer对象的数值是否相等,应该使用equals方法,而不是==运算符:
System.out.println(a.equals(b)); // 输出true |
使用equals方法时,c和d的比较结果为true,因为equals比较的是对象的数值,而不是引用地址。
Integer 缓存
Integer 的大部分数据操作都集中在值比较小的范围,因此 Integer 定义了一个缓存池,默认范围是 -128 到 127。
当我们使用自动装箱来创建这个范围内的 Integer 对象时,Java 会直接从缓存中返回一个已存在的对象,而不是每次都创建一个新的对象。这意味着,对于这个值范围内的所有 Integer 对象,它们实际上是引用相同的对象实例。
Integer 缓存的主要目的是优化性能和内存使用。对于小整数的频繁操作,使用缓存可以显著减少对象创建的数量。
可以在运行的时候添加 -Djava.lang.Integer.IntegerCache.high=1000 来调整缓存池的最大值。
引用是 Integer 类型,= 右侧是 int 基本类型时,会进行自动装箱,调用的其实是 Integer.valueOf()方法,它会调用 IntegerCache。
public static Integer valueOf(int i) { |
IntegerCache 是一个静态内部类,在静态代码块中会初始化好缓存的值。
private static class IntegerCache { |
new Integer(10) == new Integer(10) 相等吗
在 Java 中,使用new Integer(10) == new Integer(10)进行比较时,结果是 false。
这是因为 new 关键字会在堆(Heap)上为每个 Integer 对象分配新的内存空间,所以这里创建了两个不同的 Integer 对象,它们有不同的内存地址。
当使用==运算符比较这两个对象时,实际上比较的是它们的内存地址,而不是它们的值,因此即使两个对象代表相同的数值(10),结果也是 false。
String 怎么转成 Integer 的,原理是什么
String 转成 Integer,主要有两个方法:
- Integer.parseInt(String s)
- Integer.valueOf(String s)
不管哪一种,最终还是会调用 Integer 类内中的parseInt(String s, int radix)方法。
public static int parseInt(String s, int radix) |
其实就是一个简单的字符串遍历计算,不过是用负的值累减。
Object
常见方法
在 Java 中,经常提到一个词“万物皆对象”,其中的“万物”指的是 Java 中的所有类,而这些类都是 Object 类的子类。
Object 主要提供了 11 个方法,大致可以分为六类:
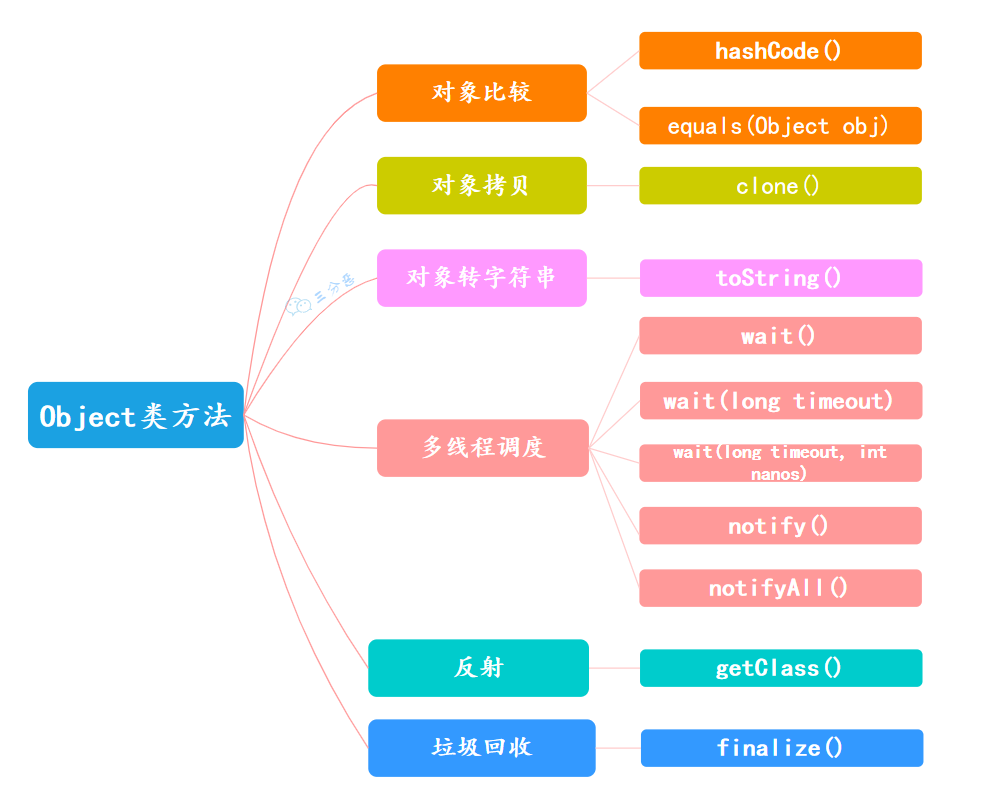
-
对象比较:
-
public native int hashCode():native 方法,用于返回对象的哈希码。public native int hashCode();
相等的对象必须具有相等的哈希码。如果重写了 equals 方法,就应该重写 hashCode 方法。可以使用 Objects.hash() 获取对象的 hashcode 方法来生成哈希码。
-
public boolean equals(Object obj):用于比较 2 个对象的内存地址是否相等。public boolean equals(Object obj) {
return (this == obj);
}如果比较的是两个对象的值是否相等,就要重写该方法,比如 String 类、Integer 类等都重写了该方法。举个例子,假如有一个 Person 类,我们认为只要年龄和名字相同,就是同一个人,那么就可以这样重写 equals 方法:
class Person1 {
private String name;
private int age;
// 省略 gettter 和 setter 方法
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj instanceof Person1) {
Person1 p = (Person1) obj;
return this.name.equals(p.getName()) && this.age == p.getAge();
}
return false;
}
}
-
-
对象拷贝:
protected native Object clone() throws CloneNotSupportedException:naitive 方法,返回此对象的一个副本。默认实现只做浅拷贝,且类必须实现 Cloneable 接口。Object 本身没有实现 Cloneable 接口,所以在不重写 clone 方法的情况下直接直接调用该方法会发生 CloneNotSupportedException 异常。
-
对象转字符串:
public String toString():返回对象的字符串表示。默认实现返回类名@哈希码的十六进制表示,但通常会被重写以返回更有意义的信息。public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}比如说一个 Person 类,我们可以重写 toString 方法,返回一个有意义的字符串:
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}可以使用 Lombok 的 @Data注解,自动生成 toString 方法。
-
多线程调度:
每个对象都可以调用 Object 的 wait/notify 方法来实现等待/通知机制:
public class WaitNotifyDemo {
public static void main(String[] args) {
Object lock = new Object();
new Thread(() -> {
synchronized (lock) {
System.out.println("线程1:我要等待");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1:我被唤醒了");
}
}).start();
new Thread(() -> {
synchronized (lock) {
System.out.println("线程2:我要唤醒");
lock.notify();
System.out.println("线程2:我已经唤醒了");
}
}).start();
}
}- 线程 1 先执行,它调用了
lock.wait()方法,然后进入了等待状态。 - 线程 2 后执行,它调用了
lock.notify()方法,然后线程 1 被唤醒了。
①、
public final void wait() throws InterruptedException:调用该方法会导致当前线程等待,直到另一个线程调用此对象的notify()方法或notifyAll()方法。②、
public final native void notify():唤醒在此对象监视器上等待的单个线程。如果有多个线程等待,选择一个线程被唤醒。③、
public final native void notifyAll():唤醒在此对象监视器上等待的所有线程。④、
public final native void wait(long timeout) throws InterruptedException:等待 timeout 毫秒,如果在 timeout 毫秒内没有被唤醒,会自动唤醒。⑥、
public final void wait(long timeout, int nanos) throws InterruptedException:更加精确了,等待 timeout 毫秒和 nanos 纳秒,如果在 timeout 毫秒和 nanos 纳秒内没有被唤醒,会自动唤醒。 - 线程 1 先执行,它调用了
-
反射:
public final native Class<?> getClass():用于获取对象的类信息,如类名:public class GetClassDemo {
public static void main(String[] args) {
Person p = new Person();
Class<? extends Person> aClass = p.getClass();
System.out.println(aClass.getName());
}
}输出结果:
com.itwanger.Person
-
垃圾回收:
protected void finalize() throws Throwable:当垃圾回收器决定回收对象占用的内存时调用此方法。用于清理资源,但 Java 不推荐使用,因为它不可预测且容易导致问题,Java 9 开始已被弃用。
异常处理:
异常处理体系
Java 中的异常处理机制用于处理程序运行过程中可能发生的各种异常情况,通常通过 try-catch-finally 语句和 throw 关键字来实现。
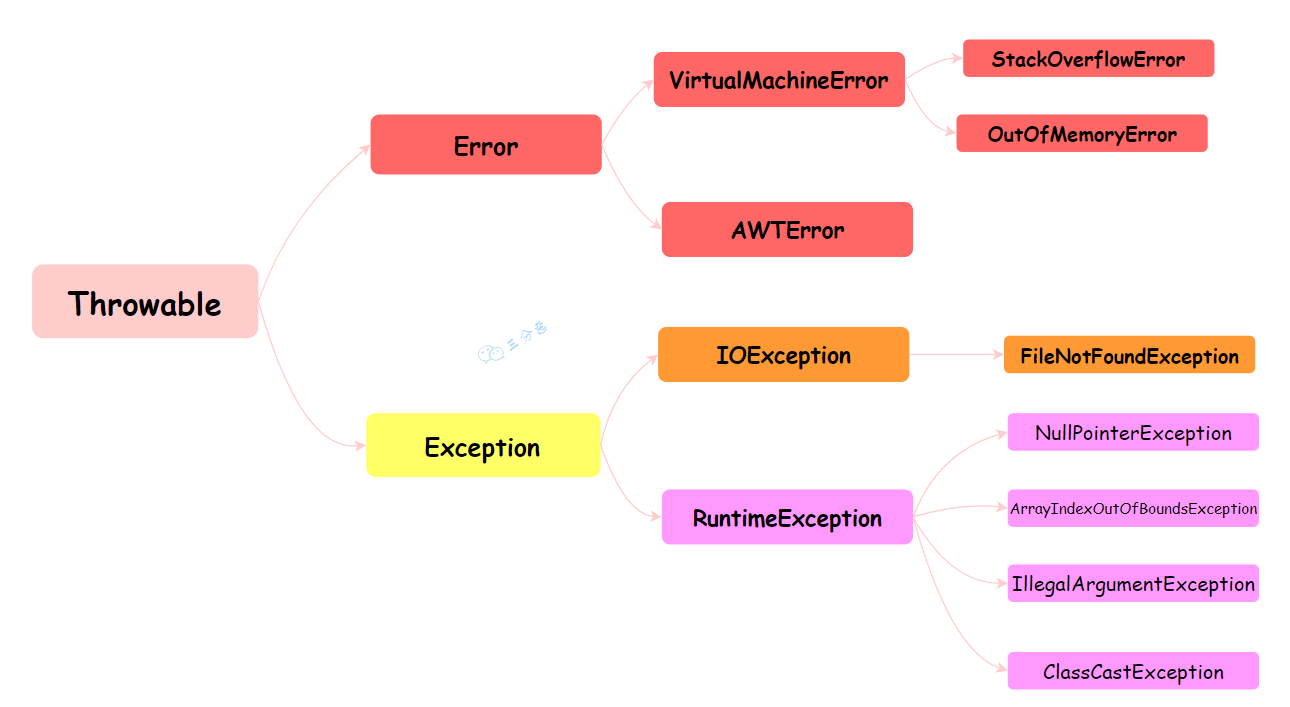
Throwable 是 Java 语言中所有错误和异常的基类。它有两个主要的子类:Error 和 Exception,这两个类分别代表了 Java 异常处理体系中的两个分支。
Error 类代表那些严重的错误,这类错误通常是程序无法处理的。比如,OutOfMemoryError 表示内存不足,StackOverflowError 表示栈溢出。这些错误通常与 JVM 的运行状态有关,一旦发生,应用程序通常无法恢复。
Exception 类代表程序可以处理的异常。它分为两大类:编译时异常(Checked Exception)和运行时异常(Runtime Exception)。
①、编译时异常(Checked Exception):这类异常在编译时必须被显式处理(捕获或声明抛出)。
如果方法可能抛出某种编译时异常,但没有捕获它(try-catch)或没有在方法声明中用 throws 子句声明它,那么编译将不会通过。例如:IOException、SQLException 等。
②、运行时异常(Runtime Exception):这类异常在运行时抛出,它们都是 RuntimeException 的子类。对于运行时异常,Java 编译器不要求必须处理它们(即不需要捕获也不需要声明抛出)。
运行时异常通常是由程序逻辑错误导致的,如 NullPointerException、IndexOutOfBoundsException 等。
异常处理方式
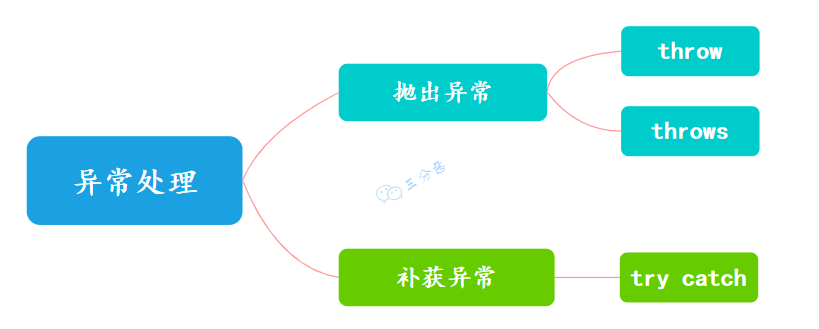
①、遇到异常时可以不处理,直接通过throw 和 throws 抛出异常,交给上层调用者处理。
throws 关键字用于声明可能会抛出的异常,而 throw 关键字用于抛出异常。
public void test() throws Exception { |
②、使用 try-catch 捕获异常,处理异常。
try { |
cath和finally的异常可以同时抛出吗
如果 catch 块抛出一个异常,而 finally 块中也抛出异常,那么最终抛出的将是 finally 块中的异常。catch 块中的异常会被丢弃,而 finally 块中的异常会覆盖并向上传递。
public class Example { |
- try 块首先抛出一个 Exception。
- 控制流进入 catch 块,catch 块中又抛出了一个 RuntimeException。
- 但是在 finally 块中,抛出了一个 IllegalArgumentException,最终程序抛出的异常是 finally 块中的 IllegalArgumentException。
虽然 catch 和 finally 中的异常不能同时抛出,但可以手动捕获 finally 块中的异常,并将 catch 块中的异常保留下来,避免被覆盖。常见的做法是使用一个变量临时存储 catch 中的异常,然后在 finally 中处理该异常:
public class Example { |
三道经典异常处理代码题
题目一
public class TryDemo { |
在test()方法中,首先有一个try块,接着是一个catch块(用于捕获异常),最后是一个finally块(无论是否捕获到异常,finally块总会执行)。
①、try块中包含一条return 1;语句。正常情况下,如果try块中的代码能够顺利执行,那么方法将返回数字1。在这个例子中,try块中没有任何可能抛出异常的操作,因此它会正常执行完毕,并准备返回1。
②、由于try块中没有异常发生,所以catch块中的代码不会执行。
③、无论前面的代码是否发生异常,finally块总是会执行。在这个例子中,finally块包含一条System.out.print("3");语句,意味着在方法结束前,会在控制台打印出3。
当执行main方法时,控制台的输出将会是:
31 |
这是因为finally块确保了它包含的System.out.print("3");会执行并打印3,随后test()方法返回try块中的值1,最终结果就是31。
题目二
public class TryDemo { |
执行结果:
3 |
try 返回前先执行 finally,结果 finally 里直接 return 了,自然也就走不到 try 里面的 return 了。
题目三
public class TryDemo { |
执行结果:
2 |
I/O
Java 中IO流分为几种
Java IO 流的划分可以根据多个维度进行,包括数据流的方向(输入或输出)、处理的数据单位(字节或字符)、流的功能以及流是否支持随机访问等。
按照数据流方法划分:
- 输入流(Input Stream):从源(如文件、网络等)读取数据到程序。
- 输出流(Output Stream):将数据从程序写出到目的地(如文件、网络、控制台等)。
按照处理数据单位划分:
- 字节流(Byte Streams):以字节为单位读写数据,主要用于处理二进制数据,如音频、图像文件等。
- 字符流(Character Streams):以字符为单位读写数据,主要用于处理文本数据。
按功能划分:
- 节点流(Node Streams):直接与数据源或目的地相连,如 FileInputStream、FileOutputStream。
- 处理流(Processing Streams):对一个已存在的流进行包装,如缓冲流 BufferedInputStream、BufferedOutputStream。
- 管道流(Piped Streams):用于线程之间的数据传输,如 PipedInputStream、PipedOutputStream。
Java缓冲区溢出的预防方法
ava 缓冲区溢出主要是由于向缓冲区写入的数据超过其能够存储的数据量。可以采用这些措施来避免:
①、合理设置缓冲区大小:在创建缓冲区时,应根据实际需求合理设置缓冲区的大小,避免创建过大或过小的缓冲区。
②、控制写入数据量:在向缓冲区写入数据时,应该控制写入的数据量,确保不会超过缓冲区的容量。Java 的 ByteBuffer 类提供了remaining()方法,可以获取缓冲区中剩余的可写入数据量。
import java.nio.ByteBuffer; |
为什么要有字节流和字符流
其实字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还比较耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。
所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
文本存储是字节流还是字符流,视频文件呢?
在计算机中,文本和视频都是按照字节存储的,只是如果是文本文件的话,我们可以通过字符流的形式去读取,这样更方面的我们进行直接处理。
比如说我们需要在一个大文本文件中查找某个字符串,可以直接通过字符流来读取判断。
处理视频文件时,通常使用字节流(如 Java 中的FileInputStream、FileOutputStream)来读取或写入数据,并且会尽量使用缓冲流(如BufferedInputStream、BufferedOutputStream)来提高读写效率。
无论是文本文件还是视频文件,它们在物理存储层面都是以字节流的形式存在。区别在于,我们如何通过 Java 代码来解释和处理这些字节流:作为编码后的字符还是作为二进制数据。
BIO、NIO、AIO的区别
Java 常见的 IO 模型有三种:BIO、NIO 和 AIO。
BIO:采用阻塞式 I/O 模型,线程在执行 I/O 操作时被阻塞,无法处理其他任务,适用于连接数较少的场景。
NIO:采用非阻塞 I/O 模型,线程在等待 I/O 时可执行其他任务,通过 Selector 监控多个 Channel 上的事件,适用于连接数多但连接时间短的场景。
AIO:使用异步 I/O 模型,线程发起 I/O 请求后立即返回,当 I/O 操作完成时通过回调函数通知线程,适用于连接数多且连接时间长的场景
BIO
BIO,也就是传统的 IO,基于字节流或字符流(如 FileInputStream、BufferedReader 等)进行文件读写,基于 Socket 和 ServerSocket 进行网络通信。
对于每个连接,都需要创建一个独立的线程来处理读写操作。
NIO
NIO,JDK 1.4 时引入,放在 java.nio 包下,提供了 Channel、Buffer、Selector 等新的抽象,基于 RandomAccessFile、FileChannel、ByteBuffer 进行文件读写,基于 SocketChannel 和 ServerSocketChannel 进行网络通信。
实际上,“旧”的 I/O 包已经使用 NIO 重新实现过,所以在进行文件读写时,NIO 并无法体现出比 BIO 更可靠的性能。
NIO 主要体现在网络编程中,服务器可以用一个线程处理多个客户端连接,通过 Selector 监听多个 Channel 来实现多路复用,极大地提高了网络编程的性能。
缓冲区 Buffer 也能极大提升一次 IO 操作的效率。
AIO
AIO 是 Java 7 引入的,放在 java.nio.channels 包下,提供了 AsynchronousFileChannel、AsynchronousSocketChannel 等异步 Channel。
它引入了异步通道的概念,使得 I/O 操作可以异步进行。这意味着线程发起一个读写操作后不必等待其完成,可以立即进行其他任务,并且当读写操作真正完成时,线程会被异步地通知。
AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(Paths.get("test.txt"), StandardOpenOption.READ); |
序列化
序列化与反序列化
序列化(Serialization)是指将对象转换为字节流的过程,以便能够将该对象保存到文件、数据库,或者进行网络传输。
反序列化(Deserialization)就是将字节流转换回对象的过程,以便构建原始对象。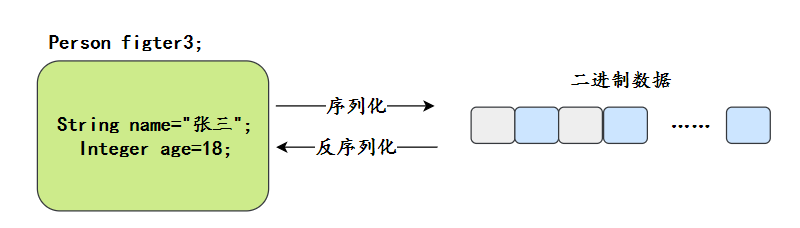
Serializable接口
Serializable接口用于标记一个类可以被序列化。
public class Person implements Serializable { |
serialVersionUID
serialVersionUID 是 Java 序列化机制中用于标识类版本的唯一标识符。它的作用是确保在序列化和反序列化过程中,类的版本是兼容的。
import java.io.Serializable; |
serialVersionUID 被设置为 1L 是一种比较省事的做法,也可以使用 Intellij IDEA 进行自动生成。
但只要 serialVersionUID 在序列化和反序列化过程中保持一致,就不会出现问题。
如果不显式声明 serialVersionUID,Java 运行时会根据类的详细信息自动生成一个 serialVersionUID。那么当类的结构发生变化时,自动生成的 serialVersionUID 就会发生变化,导致反序列化失败。
序列化机制只会保存对象的状态,而静态变量属于类的状态,不属于对象的状态。
使用transient关键字修饰不想序列化的变量。
public class Person implements Serializable { |
序列化的过程和作用
第一步,实现 Serializable 接口。
public class Person implements Serializable { |
第二步,使用 ObjectOutputStream 来将对象写入到输出流中。
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser")); |
第三步,调用 ObjectOutputStream 的 writeObject 方法,将对象序列化并写入到输出流中。
Person person = new Person("名字", 18); |
序列化的方式
- Java 对象序列化 :Java 原生序列化方法即通过 Java 原生流(InputStream 和 OutputStream 之间的转化)的方式进行转化,一般是对象输出流
ObjectOutputStream和对象输入流ObjectInputStream。 - Json 序列化:这个可能是我们最常用的序列化方式,Json 序列化的选择很多,一般会使用 jackson 包,通过 ObjectMapper 类来进行一些操作,比如将对象转化为 byte 数组或者将 json 串转化为对象。
- ProtoBuff 序列化:ProtocolBuffer 是一种轻便高效的结构化数据存储格式,ProtoBuff 序列化对象可以很大程度上将其压缩,可以大大减少数据传输大小,提高系统性能。
网络编程
Socket网络套接字
Socket 是网络通信的基础,表示两台设备之间通信的一个端点。Socket 通常用于建立 TCP 或 UDP 连接,实现进程间的网络通信。
一个简单的 TCP 客户端:
class TcpClient { |
TCP 服务端:
class TcpServer { |
RPC框架
RPC是一种协议,允许程序调用位于远程服务器上的方法,就像调用本地方法一样。RPC 通常基于 Socket 通信实现。
RPC,Remote Procedure Call,远程过程调用 |
RPC 框架支持高效的序列化(如 Protocol Buffers)和通信协议(如 HTTP/2),屏蔽了底层网络通信的细节,开发者只需关注业务逻辑即可。
常见的 RPC 框架包括:
- gRPC:基于 HTTP/2 和 Protocol Buffers。
- Dubbo:阿里开源的分布式 RPC 框架,适合微服务场景。
- Spring Cloud OpenFeign:基于 REST 的轻量级 RPC 框架。
- Thrift:Apache 的跨语言 RPC 框架,支持多语言代码生成。
泛型
泛型主要用于提高代码的类型安全,它允许在定义类、接口和方法时使用类型参数,这样可以在编译时检查类型一致性,避免不必要的类型转换和类型错误。
没有泛型的时候,像 List 这样的集合类存储的是 Object 类型,导致从集合中读取数据时,必须进行强制类型转换,否则会引发 ClassCastException。
List list = new ArrayList(); |
使用方式
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
1.泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型 |
实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456); |
2.泛型接口 :
public interface Generator<T> { |
实现泛型接口,指定类型:
class GeneratorImpl<T> implements Generator<String>{ |
3.泛型方法 :
public static < E > void printArray( E[] inputArray ) |
使用:
// 创建不同类型数组: Integer, Double 和 Character |
泛型通配符
常用的通配符为: T,E,K,V,?
- ? 表示不确定的 java 类型
- T (type) 表示具体的一个 java 类型
- K V (key value) 分别代表 java 键值中的 Key Value
- E (element) 代表 Element
泛型擦除
泛型擦除,也叫“类型擦除”。
Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的类型信息都会被擦掉。
也就是说,在运行的时候是没有泛型的。
原因:
主要是为了向下兼容,因为 JDK5 之前是没有泛型的,为了让 JVM 保持向下兼容,就出了类型擦除这个策略。
注解
Java 注解本质上是一个标记
注解可以标记在类上、方法上、属性上等,标记自身也可以设置一些值,比如帽子颜色是绿色。
有了标记之后,我们就可以在编译或者运行阶段去识别这些标记,然后搞一些事情,这就是注解的用处。
例如我们常见的 AOP,使用注解作为切点就是运行期注解的应用;比如 lombok,就是注解在编译期的运行。
注解生命周期有三大类,分别是:
- RetentionPolicy.SOURCE:给编译器用的,不会写入 class 文件
- RetentionPolicy.CLASS:会写入 class 文件,在类加载阶段丢弃,也就是运行的时候就没这个信息了
- RetentionPolicy.RUNTIME:会写入 class 文件,永久保存,可以通过反射获取注解信息
反射
反射允许 Java 在运行时检查和操作类的方法和字段。通过反射,可以动态地获取类的字段、方法、构造方法等信息,并在运行时调用方法或访问字段。
比如创建一个对象是通过 new 关键字来实现的:
Person person = new Person(); |
Person 类的信息在编译时就确定了,那假如在编译期无法确定类的信息,但又想在运行时获取类的信息、创建类的实例、调用类的方法,这时候就要用到反射。
反射功能主要通过 java.lang.Class 类及 java.lang.reflect 包中的类如 Method, Field, Constructor 等来实现。
我们可以装来动态加载类并创建对象:
String className = "java.util.Date"; |
我们可以这样来访问字段和方法:
// 加载并实例化类 |
应用场景
①、Spring 框架就大量使用了反射来动态加载和管理 Bean。
②、Java 的动态代理(Dynamic Proxy)机制就使用了反射来创建代理类。代理类可以在运行时动态处理方法调用,这在实现 AOP 和拦截器时非常有用。
③、JUnit 和 TestNG 等测试框架使用反射机制来发现和执行测试方法。反射允许框架扫描类,查找带有特定注解(如 @Test)的方法,并在运行时调用它们。
原理
Java 程序的执行分为编译和运行两步,编译之后会生成字节码(.class)文件,JVM 进行类加载的时候,会加载字节码文件,将类型相关的所有信息加载进方法区,反射就是去获取这些信息,然后进行各种操作。
JDK1.8 特性
JDK 1.8 新增了不少新的特性,如 Lambda 表达式、接口默认方法、Stream API、日期时间 API、Optional 类等。
①、Java 8 允许在接口中添加默认方法和静态方法。
public interface MyInterface { |
②、Lambda 表达式描述了一个代码块(或者叫匿名方法),可以将其作为参数传递给构造方法或者普通方法以便后续执行。
public class LamadaTest { |
③、Stream 是对 Java 集合框架的增强,它提供了一种高效且易于使用的数据处理方式。
List<String> list = new ArrayList<>(); |
④、Java 8 引入了一个全新的日期和时间 API,位于java.time包中。这个新的 API 纠正了旧版java.util.Date类中的许多缺陷。
LocalDate today = LocalDate.now(); |
⑤、引入 Optional 是为了减少空指针异常。
Optional<String> optional = Optional.of("姓名"); |
Lambda表达式
Lambda 表达式主要用于提供一种简洁的方式来表示匿名方法,使 Java 具备了函数式编程的特性。
比如说我们可以使用 Lambda 表达式来简化线程的创建:
new Thread(() -> System.out.println("Hello World")).start(); |
所谓的函数式编程,就是把函数作为参数传递给方法,或者作为方法的结果返回。比如说我们可以配合 Stream 流进行数据过滤:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6); |
其中 n -> n % 2 == 0 就是一个 Lambda 表达式。表示传入一个参数 n,返回 n % 2 == 0 的结果。
Optional
Optional是用于防范NullPointerException。
可以将 Optional 看做是包装对象(可能是 null, 也有可能非 null)的容器。当我们定义了 一个方法,这个方法返回的对象可能是空,也有可能非空的时候,我们就可以考虑用 Optional 来包装它,这也是在 Java 8 被推荐使用的做法。
Stream流
Stream 流,简单来说,使用 java.util.Stream 对一个包含一个或多个元素的集合做各种操作。这些操作可能是 中间操作 亦或是 终端操作。 终端操作会返回一个结果,而中间操作会返回一个 Stream 流。
Stream 流一般用于集合,我们对一个集合做几个常见操作
List<String> stringCollection = new ArrayList<>(); |
-
Filter 过滤
stringCollection
.stream()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
// "aaa2", "aaa1"Sorted 排序
-
stringCollection .stream() .sorted() .filter((s) -> s.startsWith("a")) .forEach(System.out::println); // "aaa1", "aaa2"
- **Map 转换**
```java
stringCollection
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);
// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1" -
Match 匹配
// 验证 list 中 string 是否有以 a 开头的, 匹配到第一个,即返回 true
boolean anyStartsWithA =
stringCollection
.stream()
.anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
// 验证 list 中 string 是否都是以 a 开头的
boolean allStartsWithA =
stringCollection
.stream()
.allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
// 验证 list 中 string 是否都不是以 z 开头的,
boolean noneStartsWithZ =
stringCollection
.stream()
.noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true -
Count 计数
count是一个终端操作,它能够统计stream流中的元素总数,返回值是long类型。// 先对 list 中字符串开头为 b 进行过滤,让后统计数量
long startsWithB =
stringCollection
.stream()
.filter((s) -> s.startsWith("b"))
.count();
System.out.println(startsWithB); // 3 -
Reduce
Reduce 中文翻译为:减少、缩小。通过入参的 Function,我们能够将 list 归约成一个值。它的返回类型是 Optional 类型。
Optional<String> reduced = |
 微信
微信 支付宝
支付宝